A couple of weeks ago on Halloween night, I was out with some friends when my advisor sent me a message to check web.mit.edu, right now. It took me a few seconds of staring to realize that an article about my masters thesis work on a nonparametric approach to detecting trends on Twitter was on the homepage of MIT. Over the next few days, it was picked up by Forbes, Wired, Mashable, Engadget, The Boston Herald and others, and my inbox and Twitter Connect tab were abuzz like never before.
There was a lot of interest in how this thing works and in this post I want to give an informal overview of the method Prof. Shah and I developed. But first, let me start with a story…
A scandal
On June 27, 2012, Barclays Bank was fined $450 million for manipulating the Libor interest rate, in what was possibly the biggest banking fraud scandal in history. People were in uproar about this, and many took their outrage to Twitter. In retrospect, “#Barclays” was bound to become a popular, or “trending” topic. But how soon could one have known this with reasonable certainty? Twitter’s algorithm detected “#Barclays” as a trend at 12:49pm GMT following a big jump in activity around noon (Figure 1).

Figure 1
But is there something about the preceding activity that would have allowed us to detect it earlier? It turns out that there is. We detected it at 12:03, more than 45 minutes in advance. Overall, we were able to detect trends in advance of Twitter 79% of the time, with a mean early advantage of 1.43 hours and an accuracy of 95%.
In this post I’ll tell you how we did it. But before diving into our approach, I want to motivate the thinking behind it by going over another approach to detecting trends.
The problem with parametric models
A popular approach to trend detection is to have a model of the type of activity that comes before a topic is declared trending, and to try to detect that type of activity. One possible model is that activity is roughly constant most of the time but has occasional jumps. A big jump would indicate that something is becoming popular. One way to detect trends would be to estimate a “jumpiness” parameter, say p, from a window of activity and declare something trending or not based on whether p exceeds some threshold.

Figure 2
This kind of method is called parametric, because it estimates parameters from data. But such a “constant + jumps” model does not fully capture the types of patterns that can precede a topic becoming trending. There could be several small jumps leading up to a big jump. There could be a gradual rise and no clear jump. Or any number of other patterns (Figure 3).

Figure 3
Of course, we could build parametric models to detect each of these kinds of patterns. Or even one master parametric model that detects all of them. But pretty soon, we get into a mess. Out of all the possible parametric models one could use, which one should we pick? A priori, it is not clear.
We don’t need to do this — there’s another way.
A data-driven approach
Instead of deciding what the parametric model should be, we take a nonparametric approach. That is, we let the data itself define the model. If we gather enough data about patterns that precede trends and patterns that don’t we can sufficiently characterize all possible types of patterns that can happen. Then instead of building a model from the data, we can use the data directly to decide whether a new pattern is going to lead to a trend or not. You might ask: aren’t there an unlimited number of patterns that can happen? Don’t we need an unreasonable amount of data to characterize all these possibilities?
It turns out that we don’t, at least in this case. People acting in social networks are reasonably predictable. If many of your friends talk about something, it’s likely that you will as well. If many of your friends are friends with person X, it is likely that you are friends with them too. Because the underlying system has, in this sense, low complexity, we should expect that the measurements from that system are also of low complexity. As a result, there should only be a few types of patterns that precede a topic becoming trending. One type of pattern could be “gradual rise”; another could be “small jump, then a big jump”; yet another could be “a jump, then a gradual rise”, and so on. But you’ll never get a sawtooth pattern, a pattern with downward jumps, or any other crazy pattern. To see what I mean, take a look at this sample of patterns (Figure 4) and how it can be clustered into a few different “ways” that something can become trending.






Figure 4: The patterns of activity in black are a sample of patterns of activity leading up to a topic becoming trending. Each subsequent cluster of patterns represents a “way” that something can become trending.
Having outlined this data-driven approach, let’s dive into the actual algorithm.
Our algorithm
Suppose we are tracking the activity of a new topic. To decide whether a topic is trending at some time we take some recent activity, which we call the observation 

Each of these examples takes a vote 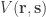

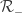


where 

Figure 5
Finally, we sum up all of the “trending” and “non-trending” votes, and see if the ratio of these sums is greater than or less than 1.

One could think of this as a kind of weighted majority vote k-nearest-neighbors classification. It also has a probabilistic interpretation that you can find in Chapter 2 of my thesis.
In general, the examples 

This approach has some nice properties. The core computations are pretty simple, as we only compute distances. It is scalable since computation of distances can be parallelized. Lastly, it is nonparametric, which means we don’t have to decide what model to use.
Results
To evaluate our approach, we collected 500 topics that trended in some time window (sampled from previous lists of trending topics) and 500 that did not (sampled from random phrases in tweets, with trending topics removed). We then tried to predict, on a holdout set of 50% of the topics, which one would trend and which one would not. For topics that both our algorithm and Twitter’s detected as trending, we measured how early or late our algorithm was relative to Twitter’s.
Our most striking result is that we were able to detect Twitter trends in advance of Twitter’s trend detection algorithm a good percent of the time, while maintaining a low rate of error. In 79% percent of cases, we detected trending topics earlier than Twitter (1.43 hours earlier), and we managed to keep an error rate of around 95% (4% false positive rate, 95% true positive rate).
Naturally, our algorithm has various parameters (most notably the scaling parameter


Figure 6
Conclusion
We’ve designed a new approach to detecting Twitter trends in a nonparametric fashion. But more than that, we’ve presented a general time series analysis method that can be used not only for classification (as in the case of trends), but also for prediction and anomaly detection (cartooned in Figure 7).

Figure 7
And it has the potential to work for a lot more than just predicting trends on Twitter. We can try this on traffic data to predict the duration of a bus ride, on movie ticket sales, on stock prices, or any other time-varying measurements.
We are excited by the early results, but there’s a lot more work ahead. We are continuing to investigate, both theoretically and experimentally, how well this does with different kinds and amounts of data, and on tasks other than classification. Stay tuned!
________________________________________________________
Notes:
Thanks to Ben Lerner, Caitlin Mehl, and Coleman Shelton for reading drafts of this.
I gave a talk about this at the Interdisciplinary Workshop on Information and Decision in Social Networks at MIT on November 9th, and I’ve included the slides below. A huge thank you to the many people who listened to dry runs of it and gave me wonderful feedback.
For a less technical look, Prof. Shah gave a great talk at the MIT Museum on Friday, November 9th:

Pingback: Early detection of Twitter trends explained | My Daily Feeds
How did you get your tweet data? Without firehose access (maybe even with), is it possible there is an inherent bias in twitter’s infrastructure that your algorithm has learned?
You can get the tweet data through the twitter API, which gives you a random sample of the firehose (though I have no idea if it is truly uniform).
Great work! Want to become able to do such things 🙂
BTW, how what tools did you use to draw such pretty figures as 2, 3, 5, 7?
Thanks!
Believe it or not, Powerpoint (for mac)!
Isn’t this incredibly basic? It’s basically photometric similarity (except you haven’t mentioned the importance of making the data scale-free here). I thought this was fairly common for comparing time series?
Indeed, the method is surprisingly simple. As far as making the data scale-free, I bet this would improve performance in practice (better accuracy given the amount of data, or less data needed for a desired accuracy). In theory, though, if we have enough data, the data itself should sufficiently cover all time scales, without doing any extra normalization.
This is a really interesting approach. I could also see it being useful with software/systems metrics (given access to a wide enough range of data).
For example, predicting when to scale up or down clusters based on what’s about to happen (rather than waiting until the servers are already somewhat overloaded). Or alerting an engineer when the system might be about to crash (rather than waiting for the metrics that indicate it has already) so they can take preventative access or at least be at their desk when it happens. Lots of possibilities where currently we’re limited to rough guesses based on point in time values and again where there’s a range of semi-predicatable patterns leading up to an event.
Yes! I’d love to apply this to other domains that are serious pain-points for people. Monitoring a complex software system or forecasting cluster usage would be two excellent things to try.
Pingback: pinboard November 18, 2012 — arghh.net
Thanks for the great explanation of a classic time-series technique, using moving average (“MA”) features with k-nearest neighbors. Have you experimented with other (nearly) non-parametric models, such as decision tree ensembles? With trees you may not need to keep as much of the training data available.
In the past I have found that kNN models like this are very sensitive to the choice of distance metric. So sensitive that the distance metric *itself* becomes something like a “parameter.” Have you tested other distance metrics, like simple Euclidean or Chebyshev?
Also, how did you fit your gamma (example weight) parameters?
Thanks for the suggestions! I have not had a chance to play with decision tree ensembles. What kinds of decisions do you think would be appropriate at each node in this case?
I have not yet tested other distance metrics, but this would be interesting to try. It is possible that the distance metric or the “features” (whatever you are measuring) have to be adjusted for different tasks.
To pick parameters, I did parameter exploration for various combinations of parameters, and estimated detection earliness and error rates using cross-validation with each parameter setting. This showed the tradeoffs between early/late and types of error. One can then pick a parameter setting manually based on one’s desired specifications.
With decision tree ensembles (i.e. random forests), you typically use a measure of feature importance at each decision node to build each path “down” the tree. When doing non-parametric classification with a decision tree ensemble (this problem), I have had good luck ranking features by information gain. That is, the reduction in Shannon entropy you get from “knowing” the value of each feature.
Be careful with cross-validation in a time-series context like this one, because it is easy to accidentally peek into the future when training your model and/or fitting your parameters via simulation. I have not looked at your code on Github yet, but staying strictly “out-of-sample” when training or optimizing parameters is crucial for not being overly confident in a model.
What if the “hot” pattern is “compressed” or “stretched” in time? Did you observe such phenomena in the rejected by your approach positive patterns?
In principle, with enough data, all the stretched versions of a pattern should be represented. In practice, it might make sense to apply something like Dynamic Time Warping in the distance metric.
Sure, with enough data, we may see those, but I would guess that DTW will bring in more noise by being flexible; I asked because I wonder – if there exist at all slow and rapid pre-trending topics patterns, and if they would relate with the abundance of “followers”.
We have not looked at the effect of number of followers, network structure, or any other micro scale things on the pre trend pattern, but it would be an interesting question for future study.
Hi, I find your approach highly interesting. Would you to explain the algorithm behind it in more detail? Or where one can find it?
Could also shoot me an email.
Thanks in advance.
Hi Li,
You can find my thesis on this topic at http://web.mit.edu/snikolov/Public/trend.pdf. Chapter 2 discusses the theory, Chapter 3 has the algorithm and pseudocode, and Chapter 4 talks about the application to Twitter data.
Great! Thanks a lot.
That link is broken
Can you make the data available? It would be nice to see it and to try couple of thoughts… I have some experience with data from this archive http://www.cs.ucr.edu/~eamonn/time_series_data, and would like to try my toolkit on the twitter data.
Unfortunately not, but you can build a similar dataset using the Twitter streaming (https://dev.twitter.com/docs/streaming-apis) and trends (https://dev.twitter.com/docs/api/1/get/trends/%3Awoeid) APIs.
I can, but how would I compare the performance? It would be much easier to tinker having the both – a working code and a sample set(s).
Hello, congratulations this looks really interesting. Is there anyway we can play with the algorithm? Are you planning to realease the code or should I implement it from the data provided in your thesis to give it a try?
Thanks a lot!
Thanks! I have the code up at https://github.com/snikolov/rumor/. At the moment, it needs a lot of cleaning up. The main detection routine is called ts_shift_detect in https://github.com/snikolov/rumor/blob/master/processing.py if you want to take a look. You might be better off starting from scratch though, since the core algorithm itself is pretty straightforward.
thanks a lot for everything! I will take a look at it and if I can clean it up or help in someway I will
Regarding your example with Twitter; how would your algorithm fare if your process of selecting the topics were truly online so that we can use them as queries ?
Very cool. I’m curious how you would ‘burn-in’ this algorithm. That is, in the absence of existing labeled trends, do you have any thoughts as to how you would start? The current algorithm seems like it might be at risk for only detecting trends that are similar to pre-labeled trends, which I suppose is the idea.
First, sorry for the absurdly late response. I think it would depend on whether you want to reproduce the results of the current trends algorithm. If you do, you could set it up by feeding it the trends and non-trends that come out of the current trends algorithm, so that you don’t have to label things manually. Otherwise, you’d have to label things manually, which would suck. You might also be able to label a small number of things manually, do something semi-supervised, and hope that there is enough data and structure in that data to make your small number of labels useful.
Perhaps with something unsupervised or semi-supervised, we can discover something intrinsic to the structure of the data that separates trends from non-trends, rather than completely relying on subjective labels.
Regarding the trends topic:
– how do you config your alpha ?
– why are you using euler number since we can approximate it with e^y ~ 1+y
Thanks
I read your thesis. It was great. I am working on kind of problem that needs detecting aspect of trends that you might be interested in. let me know if you are interested then we can get in touch via email
Hi, this is very interesting work. Well done, and congratulations for your thesis!
I have also been working on something similar. My idea is a parameterless, real-time model, which needs no training data. I call it Periscope, and it can be found at http://www.periscpe.com (the missing “o” in the name is intended). Although it was not originally built for predicting Twitter trends, I have seen that it picks up topics that later show up as trending on Twitter. At the moment, I am evaluating the accuracy of the predictions, and the latency. I will share the results as soon as they become available.
Again, congrats!
Hey Manos,
Thank you for the kind words. Sorry I’m getting to this so late. Have you made any progress on periscpe? It seems to uncover the “bleeding edge” of trends, which, though somewhat noisy, is interesting to look through to discover topics that are just emerging. Since there are so many of them and we have gotten so good at filtering out things that don’t interest us in a feed, it seems like a great emerging trend discovery tool.
Cheers,
Stan
Pingback: Early detection of Twitter trends explained
Is it known how Twitter computes its trending topics?
Mikio,
AFAIK, this (fairly general) blog post https://blog.twitter.com/2010/trend-or-not-trend and this (more detailed) lecture by Twitter engineers for a Berkeley class on big data last fall http://www.youtube.com/watch?v=duHxpSTmwW0 summarize the basic ideas about trending topics that have been publicly released.
Hi Stan,
I’m missing something basic here: how do you bracket the time series for the R+ dataset? If you take #Barclays, for instance, I’m sure there is plenty of time before and after June 27 in which it was not trending. In other words, it would seem incorrect to compare a signal to the activity of #Barclays from February and count similarity as being indicative of a trend. Do you bracket it by day?
Thanks,
-Alessandro
Alessandro,
Great question. We take the first time that the topic started trending and consider only the signal in a window of time leading up to that time. The size of this window is an experimental parameter that I varied from 1 to 9 hours.
Cheers,
Stan
Pingback: http www empiricalzeal com 2013 06 19 how… | Kathys LinkBook
Pingback: Pattern-detection and Twitter’s Streaming API - Strata
Pingback: Week Front-Loading, Missing Socks And Other Stories - Doktor Spinn
I think my question is similar to Daniel’s from February 19th. I’m looking at daily Twitter activity (just # of tweet) in countries over one year. I’m interested in certain days that see huge bursts of activity, not specific topics. How would you find a set of days that count as “bursty” and others that are “normal” to run this algorithm? I can manually choose the days, but who knows what kind of bias that would introduce. I could also figure out an “average” level of activity per day for the country, but then I’m back to a parametric approach.
Pingback: Pattern-detection and Twitter’s Streaming API | API
Hi
Actually i am working with trending topics on twitter but i am not using any algorithm. I am using jtwitter library by this library i am finding latest top 10 trends and between some period of time top trends like if you want from XX-XX-XXXX date to YY-YY-YYYY date but i want to show these trends with use of pie chart. Do you know how to calculate how much time top trend is in Trends list? With that time percentage i want to draw a pie chart…
An easy way is to repeatedly query for the current trends, say, every X minutes, and see how many times each trend appeared (call it Y times). That should give you a decent approximation of the amount of time the trend lasted: X * Y minutes. Good luck!
Pingback: Stream analytics on the fly: Beyond parameters! | Fizzog!
Hi,
I found this very interesting and I have a Python implementation of it which I’d love to check if its a correct. Its about 55 lines of code. I’m currently using to detect stock trends using PyAlgoTrade.
Do you have data that I could you to check this ? For example a set of positive reference signals, negative reference signals, observation signals, and expected results that I could you to check ?
Thanks a lot.
That’s great! I’d love to hear about any results. I unfortunately can’t share the data I used, since it’s Twitter-internal (I’m an employee). Sorry! Why not generate a dataset for stocks? It might be more useful for your application and it seems like you would need to do it anyway independently of which algorithm you apply. Good luck!
I’m doing that already.
I have have daily data for 66 stocks from 2008, 2012. I compute the simple returns, and for each signal (the simple returns signals) I’m splitting in chunks of (lets say) 50 days. I analyze the last 10 days of each chunk to determine if they trend or not, and put the previous 40 days in the corresponding bucket (trending/not-trending). I use those 40 days signals as the reference signals. This is the classification phase.
I then get data for 2013 and use your algorithm to detect upcoming trends.
What I wanted to validate is if my algorithm implementation is correct with respect to your paper. I thought that maybe you had some testcases that were not necessarily based on twitter trends.
Thanks a lot anyways.
Interesting – but I am not fully convinced. First of all, the prior classification of trend (A+) vs. nontrend (A-) may (must?) still be based on parametric model-based approaches to provide a learning set for the majority voting. Second, there is this parameter in the exponential to define the sphere of influence. Although I agree that your approach is able to learn from previous classifications for faster trend detection – can it indeed be labeled nonparametric?
Reblogged this on My Research Collections.
Pingback: Information Diffusion on Twitter | computational amusement
Pingback: Pattern-detection and Twitter’s Streaming API | The Gradient Flow
Hello and congratulations for your interesting method.
I have quickly read your thesis and I have one question.
In the 4th normalization technique (logarithmic scale) ,
what happens if the value of a time bucket is 0, meaning
that there is no tweets for a topic at this specific time range?
Thanks a lot,
Nikos
Hi Nikos,
Since this is just a heuristic, I cheat a little and add a small constant to prevent taking the log of zero. The constant can be tuned like any other parameter. Hope that helps!
Stan
Thank you for the quick response, it helps a lot!
Inspired from your thesis I try to implement a real time
version of your method using Hadoop and Storm, as my
master thesis. Hope that is ok!
I will let you know about the effectiveness of this effort
when I finish my experiments.
Best regards,
Nikos
Awesome! I’ve been thinking of doing this in storm too. Please do let me know how it turns out. I imagine it would be interesting to decide which signals to track in the first place (something I did not consider at all in my thesis). Have fun!
Hey thanks for sharing your work details. It’s interesting and helpful.
I read twitter streaming API documentations and you above article for my interest based query but I could not get information I want. I dont want to track any topic. What I want is to get top tweets from twitter based on location, category (news, entertainment, sports ..), rt_count values, type (tweets containing image, video, link). Is there any twitter API support for this? Or I need to write my own algorithm for this. can you please suggest any direction for this?
Hi Nikolav, I just read your thesis and found it very interesting. I’m a working on similar things for predicting tweets. I have althought a question about your data. You say in your thesis that “The data collection process can be summarized as follows. First, we collected 500 examples of topics that trended at least once between June 1, 2012 and June 30, 2012 (hereafter referred to as the sample window) and 500 examples of topics
that never trended during the sample window. We then sampled Tweets from the sample window and labeled each Tweet according to the topics mentioned therein.”
Isn’t there a selection bias doing so? You are choosing 1000 topics where the half is a trend topic. And then, when sampling tweets you ar labeling each tweet according to one of the topics among the 1000. But what happens then with all the tweets that don’t fit in any of these topics? While selecting 1000 topics you are in a way letting some topics out of the game, and with these, you might be getting very ‘nice results’ (because you were lucky enough to select what helps you), or very ‘bad results’ (because you were not lucky enough). Besides, if I take topics at random (among all the possible topics in the world), I’m more likely to get a non-trending topic, than a trending one, but when doing the 500/500 thing, you are taking topics were the half are trends, which is a lot I think. Have you tested your method on random sampling tweets, then topic identifying, then trend identifying? In other words, have you tried your method on a data set collection that is completed selected at random from a sampling on twitter from a certain period of time? (Without the 500+500 topics before). I’m trying to get the tweets at random, identify the topic in it (only by reading it individually), and the analyze.
I thank you a lot for your time reading this, and would be glad to know the answer to these questions. It would help me for my research.
Best regards,
Tomás
Stan, the link to the thesis is not available anymore. Could you please email it to me ? Thanks a lot.
Hi Nikolav. Thanks for sharing some details of your work. Found your classification algorithm very effective.
I have just read you thesis and could not understand the determination of the positive and negative reference sequences (R+ and R-, respectively).
Does it consist of a manual process of finding 500 examples of each class or you employed some unsupervised clustering analysis? How can I find representative enough reference sequences from my time series database?
Could you please give more details or point to a reference on that matter?
Thans again.
Marcio,
I randomly sampled from past trending topics for the positive examples and randomly sampled words from tweets for the negative examples.
First off, I really like this approach a lot, and am strongly considering using it for a trend detection project I’m working on. I understand why there are limitations about distributing the data sets you used, but is it possible to post anonymized sets of just the timestamps, counts, and class (R+ or R-) ? I’ve been thinking that it could be possible to extend this work one step further, and use the ratio R(s) as a feature into a logistic regression along with some of other features (e.g. class of the minimum- and maximum-distance reference signals, number of R+ in the top-10 closest signals, etc). Might be able to improve results a little bit.
Pingback: Beyond Trending Topics: identifying important conversations in communities | dataworks
Pingback: 老中帮老中 | ggooggoo
Pingback: Interview Preparation – Zebing Lin's blog
Pingback: Reshared | Yi's Personal Notes
Pingback: System Design Interview Prep Material | TechUtils.in